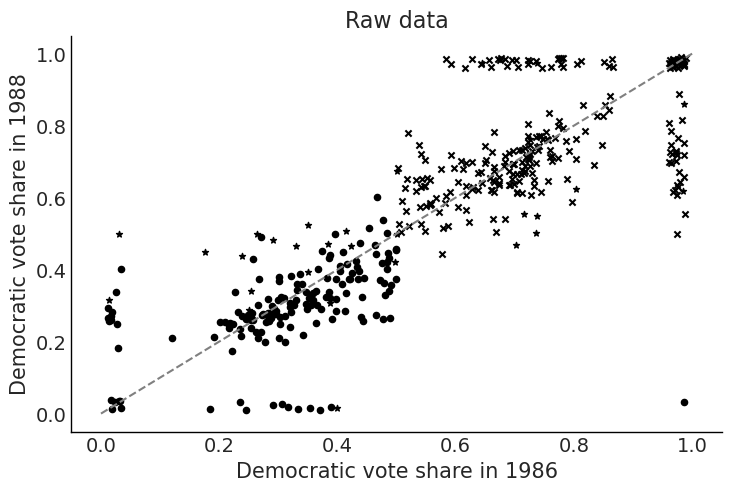
def jitt(vote):= len (vote)return np.where(< 0.1 ,0.01 , 0.04 , n),> 0.9 , rng.uniform(0.96 , 0.99 , n), vote),= jitt(congress["v86" ])= jitt(congress["v88" ])= plt.subplots()"inc88" ] == 0 ],"inc88" ] == 0 ],= "*" ,= "black" ,= 20 ,"inc88" ] == 1 ],"inc88" ] == 1 ],= "x" ,= "black" ,= 20 ,"inc88" ] == - 1 ],"inc88" ] == - 1 ],= "o" ,= "black" ,= 20 ,0 , 1 ], [0 , 1 ], color= "gray" , linestyle= "--" )"Raw data" )"Democratic vote share in 1986" )"Democratic vote share in 1988" )